
ざっくり解説!運用SEの仕事の流れについて
どうも。
意識低い系エンジニア ネモです。
もう5年近く美容室や床屋に行かずにセルフカット、セルフパーマ、セルフカラーで生きています。
バリカンがあればなんとかなるのを実感すると同時に、道具でなんでもできるって素晴らしいなと改めて感じるようになりました。
さてさてそれでは本題です。
今回は私が参画させていただいている案件で運用が始まったこともあり、
前回書いた以下の記事の続編を書こうと思います。
今回は運用でSEが行う作業の流れなどを書いていきます。
運用の動き
役割分担などは前述の前回記事を見ていただくとして、
早速運用作業の動きや流れなどを書いていきます。
基本的な作業としてはざっくりと以下3つになります。
- アラート起因やオペレータからの障害発生連絡契機の障害対応
- 定常作業
- 改善作業や作業依頼対応
結構長くなってしまいそうなので、今回は障害対応について書いていこうと思います。
障害対応の流れ
まずは障害対応の流れについてです。
- 障害検知連絡やログ監視アラート、オペレータ作業中に障害検知したとの連絡が入る。
- ITSMツールでアラート内容連携やログ取得依頼をオペレータと行いつつ、対応検討を行う。
- 並行して実機調査やログでの原因調査、一次対処を行い、業務復旧を目指す。
※基本的に運用では障害復旧までの目標時間を定義しているので、それを超えないように早期復旧を目指します。
障害時の調査
次は障害時の調査について書いていきます。
改善作業の調査などに関してはいずれ機会があったら書いていくとして、今回は障害対応にのみ絞っていこうと思います。
まず、調査には大まかに二つのパターンがあります。
- 実機の設定値や各種ステータス(ネットワークや関連ミドルウェアの状況など)、ログを見て現状調査する
- ベンダとやりとりする
1は使用するOSやミドルウェア、ソフトウェアによって異なるので、詳しくは書きませんが
ネットワーク障害時は各種ネットワーク機器の調査、ミドルウェアの調査などなど考えうる被疑箇所を徐々に絞って特定していく形になります。
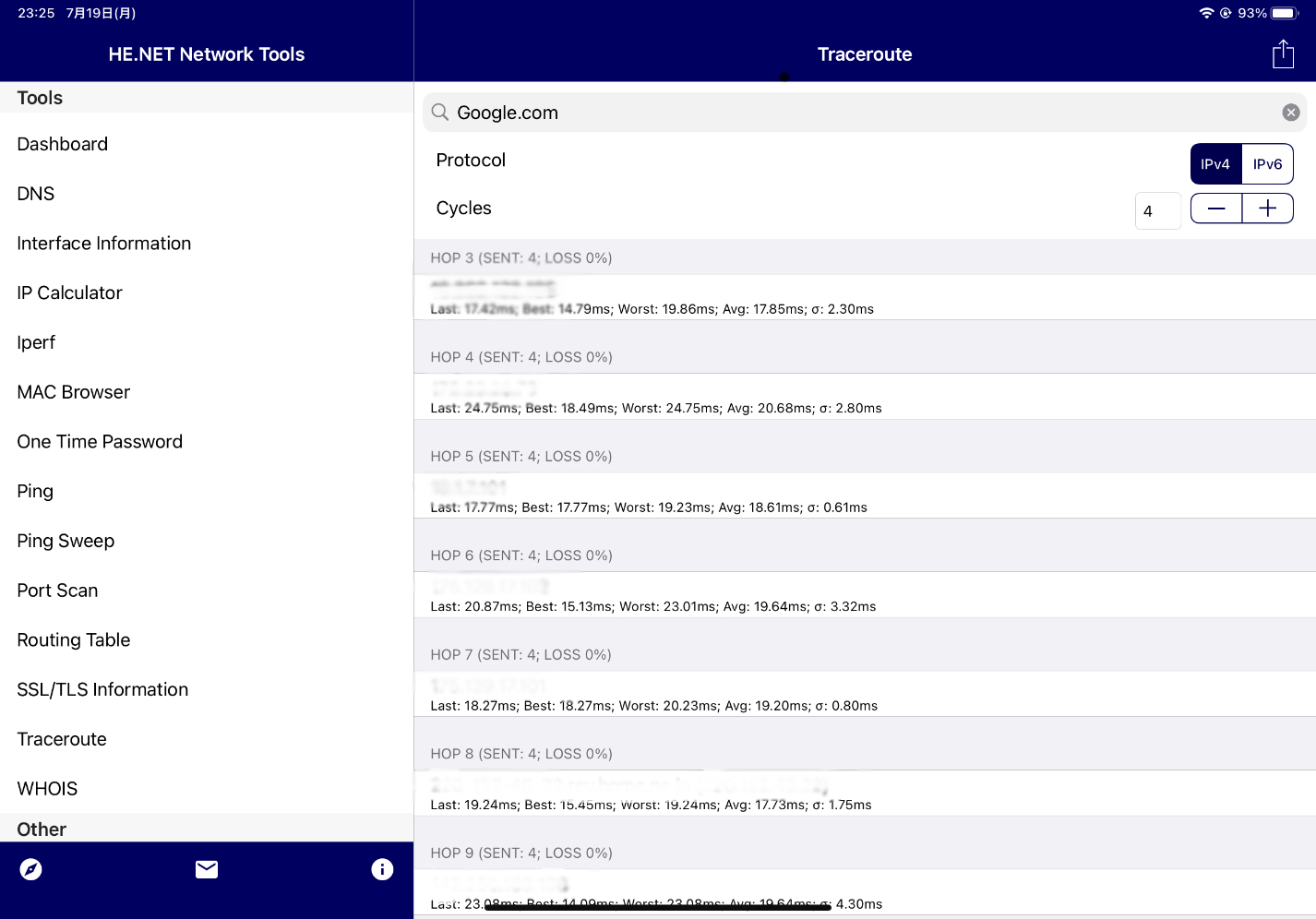
簡単なもので言えば、ネットワーク障害の場合はtraceroute(Windowsではtracert)で障害被疑箇所を特定して復旧!みたいな感じです。
例画像ではLOSS100%ではありませんが、LOSSがある箇所を被疑箇所と考え
どこまで通信できているのか、どこからできていないのかを確認し、LANケーブルの断線やルータ故障、ベンダ障害を絞っていく感じです。
2は言わずもがなですが、早期復旧のために
「こういう障害が発生していて早期復旧させたいので調べて早く直してください。」を伝えることで
復旧方法を教えてもらうというものになります。
一次対処の例
さてさて、もうこれで最後にしましょう。
一次対処は原因によって結構色々あるので、今回は簡単な例を挙げることにします。
バッチ処理中に通信断によって処理が失敗した
→ログ調査の結果NWの瞬断と分かったのでログを確認してリラン(ジョブの再実行)が成功したのか確認する
①成功している場合:その旨顧客に報告して恒久対処に移る
②失敗していた場合:原因確認後手動でリランする。
→リラン成否によってまた分岐…
案件やエラーの内容によってフローが異なりますが、大体どの案件でもこんな感じです。
さいごに
運用というのは案件によって仕組みやソフト、構成が全く違うので
覚えることが多く結構大変なことも多いですが
その分多岐に渡った作業ができるので自分のスキルアップに繋がることがあり
なるほど。と毎日のように思っています。
皆さんも運用とか(笑)と思わず、ぜひぜひやってみてください!